One-line summary:
Selenium is a powerful website automation tool and this course provides an excellent introduction to using it effectively when creating tests that would otherwise have to be executed manually.
Introduction
I've long been interested in controlling web pages programmatically and dynamically scraping data for analysis and verification. The problem doing this is the sheer flexibility of browsers and their ability to render very different combinations of HTML, CSS and JavaScript to provide similar visual and functional outputs. If you're looking to automate your testing of websites, as a black-box, this browser variability is a killer.
So finding a framework such as Selenium that provides a single, practical API (for automating browser actions) and executes these tasks against the most popular browsers is something of a revelation for me. It abstracts the complexity of writing automation scripts and acceptance tests; as a developer this is a real god-send. Hence my interest in this introductory Pluralsight course from John Sonmez.
Selenium Overview
The course begins with a quick summary of Selenium, where it came from and what automated testing can achieve. A key take-away is that it's important to know why you're writing tests and what you hope to achieve; in part this means focusing on the most business critical areas rather than trying to test every possible scenario.
Why bother with automated testing at all though? Fundamentally this is all about being able to test at a high-level, like a real user, to capture functional bugs early. The advantage over user-driven regression testing is repeatability; each test always runs exactly the same way every time and the overall system coverage is known in advance.
Selenium IDE
The Selenium IDE works only in Firefox and allows you to record commands, edit scripts and replay captured sequences in the browser. This is an excellent way to explore the capabilities of Selenium and learn commands but it's less suited to writing a suite of robust tests.
So, for example, it's very straightforward to capture a simple script that searches in a field, navigates to the link displayed and verifies that the expected text is displayed:
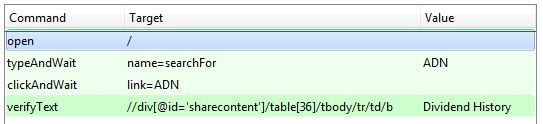
Sonmez leverages the teaching power of the IDE to demonstrate how automation works at a high level, introduces different selection commands and indicates how the code appears in WebDriver. In the latter case it's possible to directly export an ad-hoc test and get a leg-up in terms of writing the underlying C# code.
However while these captured scripts are useful, to a degree, they are rather fragile and tend to include commands that are just noise and don't add to the test itself; a problem with all recording tools. A much more powerful approach is to code your tests by hand and this is where the course heads next.
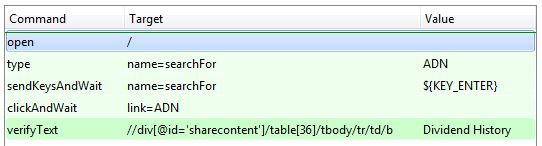
Just by way of example though while the above script looks as if it should pass just fine in fact it fails because the IDE doesn't record returns faithfully. Fortunately script editing is easy and so is the fix:
Webdriver Basics
Getting started with WebDriver is painless in Visual Studio; simply install the Selenium Nuget package and any server executables required for browsers other than Firefox. Sonmez talks through these steps thoroughly before setting up a simple script and moving onto a discussion of how to locate page elements.
For example this is all you need to instantiate a Chrome server and direct it to a web page:
IWebDriver driver = new ChromeDriver();
driver.Url = "http://www.investorease.com/";
Central to working with Selenium is understanding IWebElement: an interface that provides pretty much all of the methods and properties required to interact with any visible control. The power of this abstraction is that it allows all HTML elements to be treated equally although it comes at a price; some aspects of the interface are non-functional with some elements so you need to be aware of your context.
So getting hold of an element, such as a hyperlink, and interacting with it can be as simple as this:
var link = driver.FindElement(By.LinkText("ADN"));
link.Click();
If you're developing your own web page then it's best to place unique ids or names on the elements that you want to access. These are the fastest attributes to locate and you won't have to index through a collection of elements. If you're stuck with an existing site then Selenium provides a range of selectors (ClassName, CssSelector, Id, LinkText, Name, PartialLinkText, TagName, XPath) that allow pretty much any element to be found.
Of course some selectors, such as XPath, can be quite verbose and tightly-coupled to the underlying web page:
driver.FindElement(By.XPath("//div[@id='content']/table[36]/tbody/tr/td/b"));
Once you've found an element it can be interacted with, as a user can, by sending keystrokes and clicks. You can also chain elements together in order to drill-down to child elements; each search is within the context of its parent. This is an excellent way to nest searches and create more robust tests.
Something to watch out for though is that sending special keys to a control, such as Enter, is not as obvious as you might expect:
var search = driver.FindElement(By.Name("searchFor"));
search.SendKeys("ADN");
search.SendKeys(Keys.Enter);
As Sonmez mentions part of the secret sauce to writing solid tests is working out which selection criteria make the most sense, are clear to understand and least reliant on a specific page design. The course spends some time on this topic and I've found other good advice here. In fact without a good element location strategy you'll spend most of your time fixing broken tests rather than writing new ones.
Advanced Webdriver
Once you've got used to the basic concepts of selecting and manipulating elements Sonmez dives into more complex scenarios: radio buttons, check boxes, select lists and suchlike. Working with each of these controls requires understanding their idiosyncrasies (such as select lists having nested option elements) and the course covers these wrinkles in detail.
Some time is also spent on the XPath syntax since this allows you to navigate XML (HTML) using a file system-like model. If your page is well-formed then you have a good chance of success but the flip-side is that long expressions are fragile. A neat trick suggested by Sonmez is to use FireBug in Firefox to parse the XPath to an element. This simplifies the generation side of such expressions but they still remain "hard to read" as this typical example demonstrates:
/html/body/div/div[2]/div[1]/div[3]/div/div[1]/table[36]/tbody/tr/td/b
Another gotcha with testing is that AJAX calls and dynamic pages can cause havoc with tests as elements may not exist when you look for them. The work-around for this is to set a time-out for how long a script should wait for an element to appear before failing. The course covers both implicit and explicit waits; the former sets a global time-out for all element searches while the latter can be hand-crafted to wait for specified elements only. Both lead to more robust tests although the explicit approach requires more code:
For more information check out the C# documentation for WebDriver.
Selenium Server
The real power of Selenium is that the automation logic is abstracted into a RESTful server that can be accessed across a network. The course delves into this API and the JSON data passed when executing commands on the server. The beauty of this is that you can examine a log-file directly and see how obviously commands are relayed to the server:
COMMAND FindElement {
"locator": "name",
"using": "name",
"value": "searchFor"
}
A consequence of this server-side approach is that tests can be executed remotely and machines can be marshaled together as a grid of server nodes; each node can provide a different browser configuration. Selenium makes it very easy to set up a hub and nodes with the result that tests can be run in parallel to either speed-up the entire test suite or provide coverage of different browser/OS combinations.
An especially impressive side-effect of this architecture is that it's easy to off-load all of your regression-testing onto a cloud-based third-party such as BrowserStack. If your website is available over the internet then this seems like an excellent way to outsource the administration overhead.
Building a Framework
To get the most out of Selenium, and automate anything but the most simple test, a black-box framework is the next step. This framework is specific to your web application and acts to abstract the actions that a user can take from the implementation detail. The reason for this is so that non-developers can write and run tests without any knowledge beyond that of the domain.
Sonmez allocates just under an hour to this topic and it's clear that this is only an introduction (he has a follow-on course). Even so he demonstrates how to think about your domain and map logical objects such as pages, shared sections etc. so that tests can work against high-level methods on these objects. Essentially you're creating an internal, bounded, domain-specific language to ensure that writing tests is easy even at the expense of making the framework harder to develop.
His work-through here of creating a framework from scratch is pitched at just the right level; you get to look over Sonmez's shoulder to pick up tricks like setting page elements declaratively and using a page factory to initialise element locator's. He also provides some useful rules-of-thumb:
Don't:
- make your test declare variables for page data
- new up objects when the framework methods can be static
- manage page state outside of the framework
- have access to browser functionality in the test
Do:
- reduce the number of parameters in methods to a minimum
- use default values for input controls when possible
- only reference page elements in one place (DRY)
Can do:
- use enumerations and constants to simplify
- make framework API easy to use for non-developers
Conclusion
This course provides a very practical introduction to Selenium and what you need to know to use the tool most effectively. Some of the practices that Sonmez advocates are certainly non-standard and perhaps poor programming practice in other situations; however when you need to create a simple framework that mirrors your web site then this is a great way to get up to speed.
If you would like to know more then either check out the course or look though these articles on Sonmez's Simple Programmer website.